메모리 할당과 매핑
우리는 코드를 짤 때, 실제 메모리 위치를 알고 코드를 쓰지 않는다. count := 10 이라는 코드를 쓰면, count라는 변수가 메모리 어디에 위치하는지를 알고 짜는 것은 아니다. 프로그램을 동작시키려면 메모리에 올려야 하는데, 이 과정에서 발생하는 우리가 짠 코드가 실제 메모리에는 어떻게 올라가고, 어떻게 주소를 찾아가는지에 대한 이야기이다.
Continuous Memory Allocation
연속 메모리 할당 방식은 초기 버전의 메모리 할당 방식에 해당한다. 가장 쉬운 방법으로는 고정된 크기로 메모리를 나눠 프로세스에게 할당해주는 방식이 있고, 효율적인 메모리 분배를 위해 파티션을 프로세스 크기에 따라 나누는 방법이 있다.
Fixed Partition (FPM, 고정 분할)
이름대로, 고정된 크기로 메모리를 나누는 방식이다. 각 분할마다 한 프로세스를 가지게 되며, 이때 분할의 개수를 다중 프로그래밍 정도(Multiprogarmming Degree)라고 한다. 한 분할이 비게 되면 프로세스가 입력 큐(input queue)에서 선택되어 빈 분할로 들어오게 된다. 이 방식은 내부 단편화와 외부 단편화 모두 발생할 수 있다.
Variable Partition (VPM, 가변 분할)
가변 분할 방식에서는 어떤 부분이 사용되었는지를 파악하는 테이블을 사용해야 한다. 초기에는 하나의 큰 사용 가능한 블록, hole이 있는 상태라고 한다. 프로세스가 input queue에 들어오면 프로세스가 사용할 메모리를 확인하고, 남은 공간이 있다면 필요한 메모리만큼 할당해준다. 이 방식에서는 내부 단편화가 발생할 수 없지만, 여러 프로세스에 메모리를 할당하고 빼주는 과정을 거치다 보면 외부 단편화 문제는 발생할 수 있다. 예를 들어, 다음 시나리오를 생각해보자.
1 | 매모리 공간 55MB |
위 시나리오에서 초기 상태, 메모리 사용 상태를 파악하는 파티션 테이블은 다음과 같다.
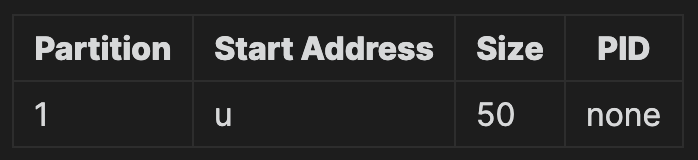
P4까지 적재된 후의 상태는 다음과 같다.
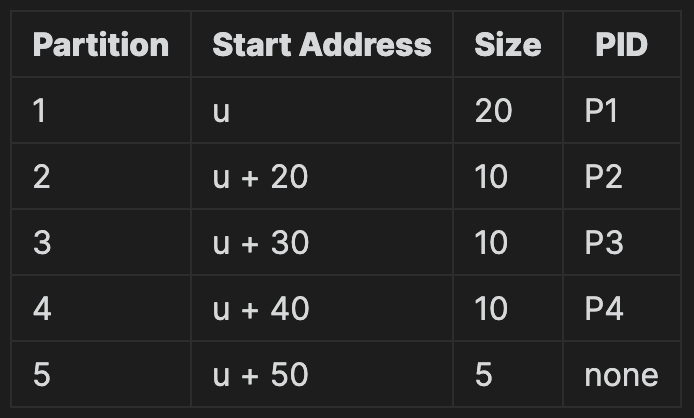
이제 P1, P3, P4가 종료 되고 나면 Partition 1, 3, 4는 빈 공간이 되고, 3, 4번 파티션이 합쳐진다.
이렇게 빈 영역을 하나의 파티션으로 합치는 것을
Coalescing holes(공간 통합)라고 한다.
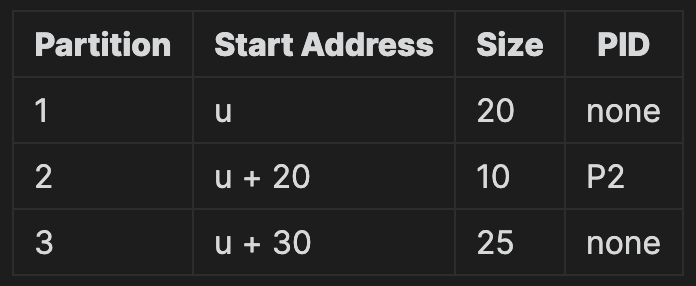
현재 남은 공간은 총 45MB이지만, 이는 연속되지 않았기 때문에 P5를 적재할 수 없는 상태이다. 즉, 외부 단편화가 발생하는 상황인 것이다.
메모리 배치 전략
위와 같은 예시 상태에서, P5가 10MB라고 가정해보자. 현재 남은 파티션은 1, 3이고 두 파티션 모두 적재할 수 있는 크기이다. 그렇다면 어디에 배치할 수 있을까? 이것을 결정하는 문제의 해결책은 대표적으로 최초 적합(First-fit), 최적 적합(Best-fit), 최악 적합(Worst-fit)이 있다.
최초 적합 (First-fit)
메모리 가용 파티션 중 첫 번째로 사용 가능한 공간을 할당해준다. 검색 시작은 집합의 시작에서부터 하거나, 지난 번에 검색이 끝났던 위치부터 시작할 수 있다.
지난 번에 검색이 끝났던 위치부터 시작하는 경우를 Next-fit으로 구분하기도 한다. 이 방식을 사용하면 메모리가 한 쪽만 지나치게 사용되는 문제를 해결할 수 있다.
최적 적합 (Best-fit)
사용 가능한 공간들 중에서 가장 작은 것을 선택한다. 리스트가 크기 순서로 되어있지는 않으므로 모든 리스트를 탐색해야 하는 오버해드가 존재한다. 이 방식은 아주 작은 파티션을 만들어낸다.
최악 적합 (Worst-fit)
가장 큰 가용 공간을 선택한다. 마찬가지로 리스트가 크기 순서로 정렬되어있지 않다면 모두 탐색해야 한다. 이 방식은 남게 되는 공간이 비교적 클 확률이 높다.
이 세 가지 방식 중 어떤 것이 더 낫다는 이론적으로 확정할 수는 없지만 모의 실험을 해봤을 때, 시간과 메모리 이용 효율 측면에서 최악 적합이 가장 안 좋았고, 최초 적합과 최적 적합이 공간 효율성은 비슷했지만 속도 면에서 최초 적합이 더 빠르게 나타났다고 한다.
Non-Continuous Memory Allocation
어떻게 하면 외부 단편화 문제를 완화할 수 있을까? 가변 분할 방식에서 외부 단편화는 프로세스가 메모리에 적재 되었다가, 빠지는 과정을 반복하면서, 불연속적인 공간이 남는 것으로 인해 발생했다. 그렇다면, 이런 불연속한 부분을 사용 중인 영역을 밀어 올려 없애는 걸 생각해볼 수 있을 것 같다. 이 방식을 Storage Compaction(메모리 압축)이라고 한다. 프로세스 처리에 필요한 적재 공간을 확보해야 할 때 사용할 수 있다. 예를 들어서, 위 테이블을 재배치 하면 다음과 같이 변경된다.
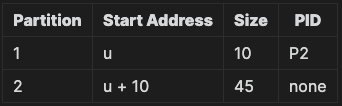
그러나 이 방식은, 프로세스를 모두 중지 해야 하고, 많은 시스템 자원을 소비하는 방식이다.
이 문제를 해결하는 다른 접근 방식은 한 프로세스의 논리 주소 공간을 여러 비연속적인 공간으로 나눠 필요한 크기의 공간을 사용할 수 있을때 메모리에 할당해주는 방식이다. 이를 Non-Continuous Memory Allocation이라고 한다. 정확하게는, 사용자 프로그램을 여러개의 블록으로 분할하고, swap-device에 모두 두고, 실행시 필요한 블록만 메인 메모리에 적재하는 방식이다. 이를 구현한 방식이 페이징(Paging)과 세그먼테이션(Segmentation)이다. 두 방식은 결합되어 사용될 수도 있다
Address Mapping
Address Mapping은, 연속 할당 방식에서는, 상대 주소를 물리 주소로 “재배치”하는 작업을 뜻했다. 불연속 메모리 할당 방식에서는 Virtual Address (가상 주소) 개념이 등장한다. 이는 연속 메모리 할당 방식의 “상대 주소”와 같다고 볼 수 있다. Real Address는 물리 주소와 같은 소리이고, 실제 메모리 주소를 뜻한다. 불연속 메모리 할당 방식의 메모리 매핑은 가상 주소를 실제 주소로 바꿔주는 과정이다.
1 | [User process의 Virtual Address] -> (Address Mapping) ->[Real Address] |
논리적, 가상적의 뉘앙스의 메모리는 프로그램이 가지고 있는 연속을 가정한 가상의 주소 형태라고 볼 수 있다. 대체적으로, 시작점을 찾을 수 있는 단서와 시작점으로부터 얼마나 많이 떨어져 있는가와 같은 튜플로 구성된다. 물리적, 실제의 뉘앙스의 메모리는 메인 메모리의 위치이다.
Block Mapping
사용자 프로그램을 블록 단위로 분할하고 관리하는 시스템에서의 매핑 방식이다. 가상 주소를 블록 숫자와 얼마나 시작점에서 떨어져있는지에 대한 정보를 가지고 표현한다.
즉, V = (b, d)로 표현하는데, b는 block number를 뜻하고, d는 displacement를 의미한다.
displacement는 쉽게 말해offset이다.block number로부터 블록의 실제 메모리 주소를 가지고, 해당 Instruction이 시작점으로부터 얼마나 떨어진 명령인지 알려주는 역할을 한다.
Address Mapping 정보는 Block Map Table(BMT)에서 관리된다. 프로세스마다 하나의 BMT를 커널 공간에 가지고 있다. BMT가 관리하는 정보는 대략 다음과 같다.
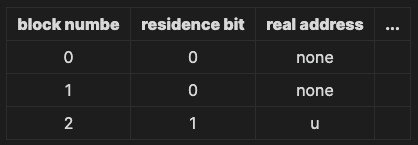
residence bit는 해당 블록이 메모리에 올라간 상태인지를 나타내주는 비트이다.
V = (b, d)로 표현되면, 먼저 BMT에서 b에 해당하는 열을 찾는다. 해당 열에서는 블록이 메모리에 적재된 상태인지 아닌지 확인 후, 적재된 상태라면 Real Address를 받아와서 d와 함께 명령어 주소를 찾는다. 적재되지 않은 상태라면 해당 블록을 메모리에 올리고 BMT를 업데이트 하고 Real Address를 받아와 명령어 주소를 계산한다.
사용자 프로그램을 여러 개의 블록으로 분할하고, swap-device에 모두 두고, 실행 시 필요한 블록만 메인 메모리에 적재하는 방식이다.
> 이 방식은 구체적인 구현이라기 보단, Non-continuous Memory Allocation에서 주로 사용하는 메모리 매핑 방법이다. 이후, 구체적으로 페이징 방식이나, 세그먼테이션 방식에서 어떻게 주소를 찾아주는지 나온다.
Paging System
프로그램을 같은 크기의 블록으로 분할하는 방식이다. 나누어진 블록을 Page(페이지)라고 부르고, 메모리의 분할 영역을 Page Frame(페이지 프레임)이라고 부른다. 페이지와 페이지 프레임은 같은 크기이다. 프로세스는 분할된 페이지로 나눠져 예비 저장 장치 또는 파일 시스템에 놓여진다. 나눠진 페이지 중 사용되는 페이지를 메모리에 올리는 방식이다.
교과서와 다르게, 강의에서는 예비 저장 장치, 파일 시스템은
Secondary Storage/Swap Device로 지칭되었는데 같은 의미로 봐도 될 것 같다.
우선 가장 큰 특징은 논리적 분할이 아니라 크기에 따른 분할이다. 이러한 특징으로 인해, 이후 세그먼테이션에서 확인할 수 있겠지만, 페이지 공유나 보호 과정이 복잡하다. 그러나 단순한 설계 방식으로 효율적으로 관리할 수 있다. 또한 외부 단편화는 발생할 수 없지만, 내부 단편화는 발생할 수 있다.
OSX의 기본 페이지 사이즈는 4096Bytes인 것 같다.
vm_stat명령어로 터미널에서 현재 가상 메모리 상태를 확인할 수 있다. 나타내는 구체적인 정보는 이 링크에서 확인할 수 있다.
Address Mapping
위의 블록 매핑 방식과 유사하다. 블록이라는 이름 대신 페이지를 사용하는 것이라고 볼 수 있다. 가상 주소를 다음과 같이 표현할 수 있다.
1 | V = (p, d) |
위 정보와 함께, 물리 주소를 찾기 위해 페이지 PMT(Page Map Table)를 사용한다. 페이지 테이블은 대략 다음과 같이 생겼다.

페이지 맵 테이블은 커널 안에(메모리 안에) 있다. 다음과 같은 프로세스를 따른다고 볼 수 있다.
- 프로세스의 PMT가 저장된 주소
b에 접근 - PMT에서 page p의 엔트리를 찾는다. (
b + p * entrySize) - 찾아진 entry의
residence bit검사residence bit == 0인 경우,page fault라고 부른다.
swap device에서 해당 page를 메모리에 적재하고 PMT를 갱신 후 3-2 수행
이 과정은 컨텍스트 스위칭이 발생하고, 오버해드가 크다.residence bit == 1인 경우, 해당 entry에서page frame numberp’를 확인
- p’의 가상 주소의
d를 사용해 실제 주소r을 만든다. (r = p' * pageSize + d)
지금까지 소개한 방법은 Directed Mapping이라는 이름으로 불린다. 커널 위의 매핑 테이블을 메모리에서 찾아오는 방식인데, 이 방식에서는 한 가지 문제점이 있다. 실제 주소를 얻기까지 메모리 접근을 두 번 해야한다는 것이다. 첫 번째는 PMT에 접근하기 위해서, 두 번째는 실제 메모리에 접근하기 위해서. 이 문제를 해결하기 위해서 Associative Mapping이라는 방법을 사용하는데, 간단히 말해서 TLB를 사용하는 방식이다.
TLB(Translation Look-aside Buffer)라는 특수한 캐시 하드웨어를 사용해, 이곳에 PMT를 적재하는 방식이다. TLB는 page number를 받으면, 페이지 테이블을 병렬적으로 탐색해 굉장히 빠르게 page frame number를 가져올 수 있다. 다만, TLB는 아주 비싸기 때문에, 작은 크기이다. 따라서, 큰 PMT를 다루기는 어렵다. 따라서, 일반적으로 PMT와 TLB를 함꼐 사용한다. PMT는 그대로 메모리 공간에 올려두고, PMT 일부만 TLB에 올리는 방식이다.
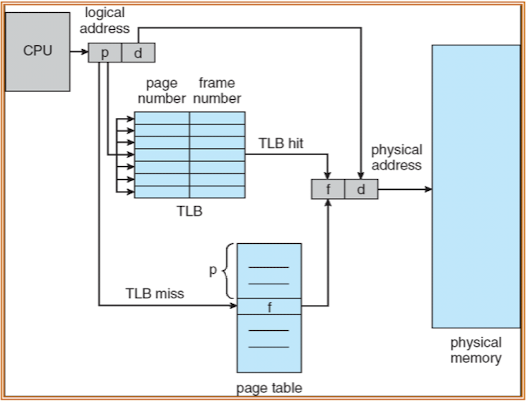
만약 찾고자 하는 Page가 TLB에 없다면, PMT에서 가져와야 한다. 이때, 이미 TLB가 모두 차있다면, 대체해야 하는데 이 정책 중 일반적인 것이 최근에 가장 적게 사용된 엔트리를 빼는 것이다. 이는 메모리 지역성과 유관하다.
Segmentation
페이징 시스템은 논리적 단위가 아닌, 크기에 따라 프로세스를 나누기 때문에, 페이징을 공유하고 보호하는 것에서 어려움이 있다. 세그멘테이션 시스템은 프로세스를 논리적 블록으로분할한다. 즉, 프로그래머가 생각하는 모양대로 메모리를 분할해 적재해준다. 따라서, 블록의 크기는 서로 다를 수 있고 페이징 시스템에서 처럼 메모리를 미리 분할할 수도 없다.
이 방식은 내부 단편화가 발생할 일이 없지만, 외부 단편화는 발생할 수 있다. 또한 세그멘트를 공유하거나 보호하는 작업을 하기 쉽지만, Address Mapping이나, 메모리 관리에서 오버헤드가 비교적 크다.
Address Mapping
Non-continuous Allocation 방식의 Address Mapping의 방식과 마찬가지로, 가상 주소를 다음과 같이 표현한다.
1 | V = (s, d) |
페이징 시스템에서 사용한 것처럼 SMT(Segment Map Table)라는 매핑 테이블을 사용한다. 매커니즘도 PMT와 유사하다. PMT와 비교하자면, segment length와 protection bits가 추가되어있다.

위와 같은 형태라고 볼 수 있는데, 추가된 두 필드는 다음과 같은 역할을 한다.
segment length: 세그먼트의 크기를 기록한다. 실제 주소를 찾을때, 세그먼트 사이즈를 초과해 접근하지 않도록 만들어준다.protection bits: 세그먼트(예를 들어 함수나 데이터)에 대한 프로세스의 권한을 적는다.
읽기: R / 쓰기: W / 실행: X / 추가: A 비트가 있다고 한다. 위에서는 추가된 두 필드라고는 하지만, 실제로 페이징 시스템에도
protection bits는 있는 것으로 설명한다.
매핑을 할때는 다이렉트 매핑 과정을 거친다.
V = (s, d)와 함께SMT가 저장된 주소b에 접근해 필요한 entry를 계산해낸다. (b + s * entrySize*)SMT의 entry에 대해 다음 단계를 순차적으로 수행한다.residence bit가 0인 경우 (segment fault),swap-device로부터 해당 segment를 메모리에 적재하고,SMT를 갱신한다.d가segment length의 길이보다 크다면, segment overflow exception 처리 모듈을 호출한다.protection bits를 확인해, 허가 되지 않은 연산인 경우 segment protection exception 처리 모듈을 호출한다.
- 실제 주소
r을 찾아 명령어를 처리한다.
Paging System에서 처럼 TLB를 사용해서 메모리에 두 번 접근하는 오버헤드를 줄일 수 있다.
Memory Manangement
VPM과 유사하게, 세그먼트를 적재할 때, 그 크기에 맞춰 동적으로 메모리를 분할한 후 적재한다. 이를 관리하는 파티션 테이블이 요구된다. 아래 구성과 같이 파티션 테이블을 관리한다.

Hybrid System
페이징 시스템과 세그멘테이션 시스템의 장점을 결합한 시스템이다. 프로그램을 다음과 같이 분할한다.
- 논리 단위의 Segment로 분할
- 각 Segment를 고정된 크기의 Page들로 분할
메모리에 적재할 때는 페이지 단위로 적재하게 된다.
Address Mapping
가상 주소는 다음과 같은 형태로 주워진다.
1 | V = (s, p, d) |
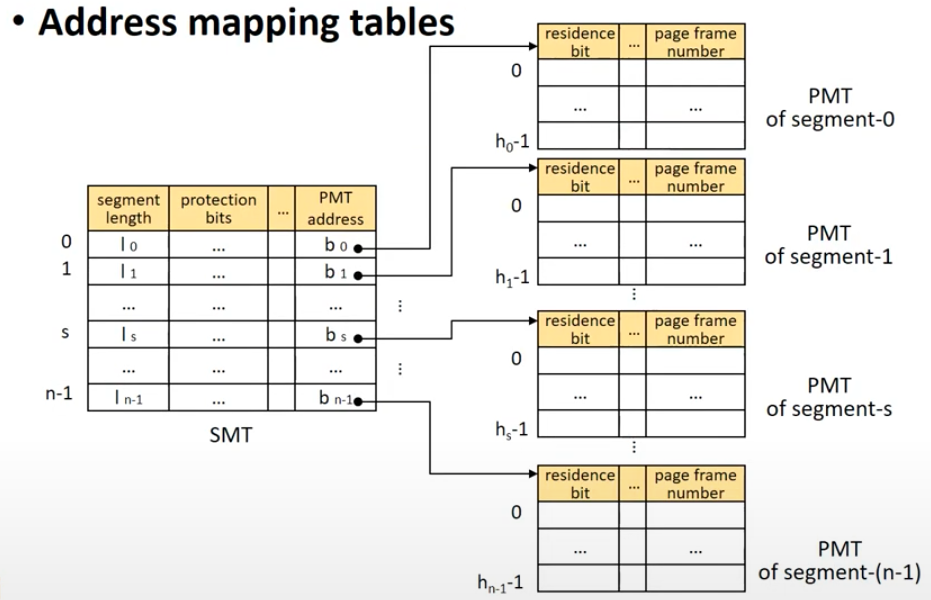
매핑을 위해 SMT와 PMT를 모두 사용해야 한다. 각 프로세스마다 하나의 SMT가 존재하고, 하나의 세그먼트마다 하나의 PMT를 갖는 구조이다. SMT 테이블은 마지막에 실제 주소 대신, PMT의 베이스 주소를 알려준다. 아래는 하이브리드 시스템에서의 SMT이다.

이전 SMT테이블과 다른 모습은, 첫 번째로 resident bit가 없다는 점이다. 실제 메모리에 올라가는 것은 Page이기 때문에 residence bit는 불필요하다. 두 번째는, 위에서 언급한 것처럼 실제 주소를 매핑하고 있지 않고, 해당 세그먼트의 PMT 메모리 주소를 매핑한다.
PMT는 페이징 시스템에서 봤던 것과 동일한 모습이다.
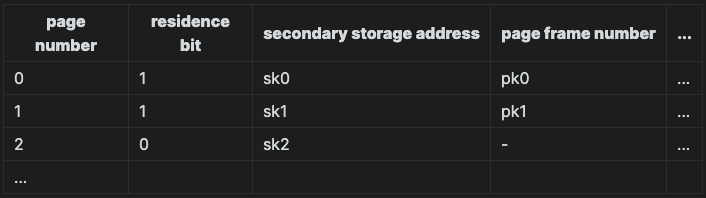
이런 형태의 테이블 구조로, 아래와 같이 프로세스를 나눈다.
아래는 다이렉트 매핑 방식에서의 메모리 매핑 플로우이다.
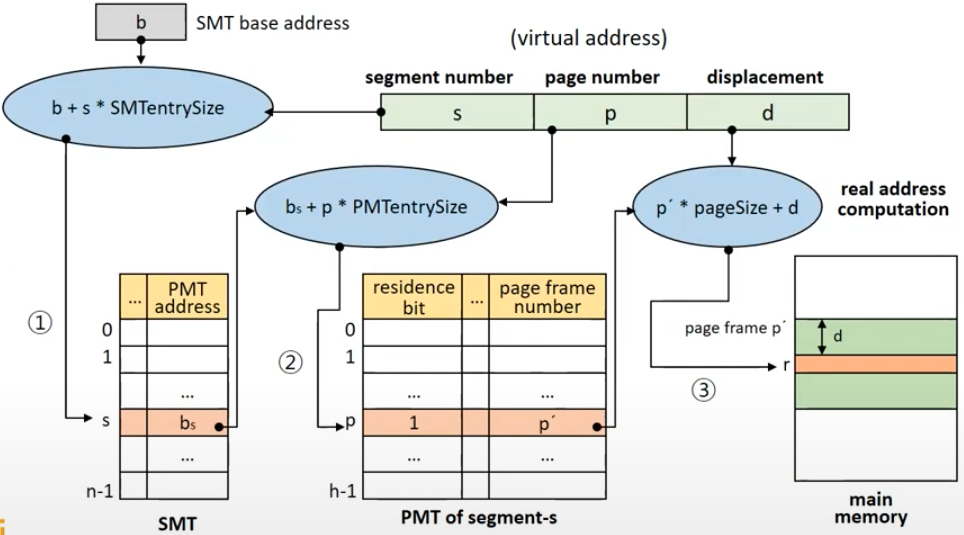
이런 시스템을 사용했을 때, 실제 메모리에 접근하는 것을 포함해서 세 번을 접근해야 한다. 또한, 테이블 수도 증가하므로, 메모리 소모도 비교적 커지고, 매핑 과정 자체가 길어진다.
이런 오버헤드가 있지만, 사용함으로써 얻는 장점이 크기 때문에 사용되는 것이라고 볼 수 있다고 한다. Page sharing, protection에 강점이 있고, 메모리 할당 및 관리에 드는 오버헤드가 작다.