etcd deep dive - Data Model
etcd 공식 페이지에 가보면 “A distributed, reliable key-value store for the most critical data of a distributed system”라고 설명하고 있다. ZooKeeper와 유사하지만 gRPC를 베이스로 하는 현대적인 코디네이터 역할을 한다. 메타 데이터를 담기 위한 Key-Value 저장소로 사용이 되는 편이고 가장 유명한 활용처는 쿠버네티스가 아닐까 싶다. 최근 사용할 일이 생기고 있어서 깊게 공부해보려고 하나씩 파헤치고 있다. 첫 글은 etcd의 데이터 모델이다.
etcd는 고맙게도 공식 페이지나 CNCF 발표 영상 등에서 구체적인 디자인들에 대해 여러 방법으로 알려주고 있다. 이번 글은 etcd의 공식 문서의 Learning 섹션에서 제공해주는 etcd data model을 정리한 글이다.
Overview
etcd는 멀티 버전 Key-Value 스토리지이다. 즉, 이전 버전의 키값 쌍을 새 값으로 대체하기 전까지 보존한다. etcd는 여러 버전의 데이터를 효율적이고 불변 데이터 형태로 관리한다. 불변 데이터라고 하면 In-Place 형태로 디스크의 데이터를 업데이트하지 않고 아니라 항상 새로운 버전을 만드는 것을 말한다. In-Place 방식보다 공간 측면에서는 덜 효율적일 것 같긴 한데 “효율적”이라는 키워드를 사용한 이유는 이후 후술한다. 아무튼 이렇게 과거 버전도 모두 가지고 있게 되므로 특정 키에 대한 과거 버전 데이터들은 나중에도 접근이 가능하고 Watchable 하다. 한편으로는 과거 버전이 무한히 늘어나는 것을 막기 위해 Compaction을 진행하기도 한다.
Logical View
etcd를 논리적인 측면에서 봤을 때 간단히 말하자면 바이너리 키 공간이다. 키는 복수의 Revision(리비전)을 가지고 있을 수 있다. 리비전은 스토리지의 트랜잭션 번호라고 생각해도 된다. 정수 형태이며 스토어가 세팅되면 초기 리비전 값은 1부터 시작하게 된다. Atomic 한 요청 단위(트랜잭션)이 수행될 때마다 새로운 리비전으로 값을 쓰게 된다. 즉, 트랜잭션마다 리비전이 단조 증가하게 된다. 과거의 리비전 역시 스토리지 내에서 일정 기간 보유하고 있어서 실제 쿼리를 통해 접근이 가능하며, 리비전 정보 역시 인덱싱되어 있어서 특정 리비전을 기준으로 쿼리하거나 Watch 하는 것도 빠르게 처리할 수 있다. 만약 저장소가 압축을 수행하면 압축 이전의 리비전들은 모두 삭제되며 쿼리할 수 없게 된다.
1 | $ etcdctl compact 5 |
그러면 리비전 Overflow가 생길 수 있는 건가? 라고 생각했는데, 역시나 이런 생각을 한 사람이 있었고 이슈에서 찾아볼 수 있었다. 그러나 그러한 걱정은 하덜 말라는 답변. 초당 2만 번씩 53억 년 동안 Mutation이 발생해야 오버플로우가 발생한다고 한다.
etcd는 단순히 put과 delete로 스토리지 안의 키를 변경한다. 키에 대한 값은 리비전에 대한 정보뿐 아니라 키의 변경 버전을 기록한다. Protocol Buffer 메시지 타입은 다음과 같이 생겼다.
1 | message KeyValue { |
키를 생성하면 키의 버전이 증가하는 것과 동일하다. 만약 기존에 해당 키가 존재하지 않았다면 1부터 시작하게 하는 것이고 기존에 해당 키로 이미 값이 존재한다면 그 키에 대해 버전을 올리는 것과 같다. 키를 삭제하는 것은 해당 키에 대한 Tombstone을 만들고 해당 키의 버전을 0으로 만드는 것과 같다. 압축이 발생하면 압축 이전의 모든 세대가 제거되고 가장 최근 버전만 남게 된다.
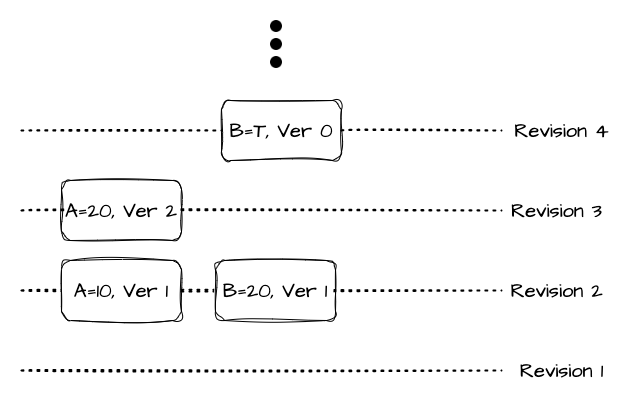
글에서는 생명 주기로 표현하는데, 굳이 생명 주기라고 할만한 건 없는 것 같다. 그냥 키가 리비전을 통해 여러 버전을 가지고 있을 수 있고 해당 변경 사항들이 불변 데이터처럼 쌓인다는 게 본질적인 내용이다.
Tombstone은 Append Only Log 같은 데이터에서 삭제 표기를 하기 위해 사용하는 데이터이다.
Physical View
실제 구현 레벨에서 etcd는 크게 두 가지 레이어를 통해 스토리지를 구성한다.
- Persistent B+tree
- In-memory B Tree
Persistent B+Tree
영구 저장소로 B+Tree를 사용하고 있다. B+Tree에 키를 저장할 때 다음과 같이 3개의 튜플로 키를 만들어준다.
- Major: 해당 키를 들고 있는 Revision을 의미한다.
- Sub: 같은 리비전 내의 다른 키들과 구분을 위해 사용된다. (아마 개발자가 설정하는 값이 아닐까)
- Type: 특수한 값을 위한 Optional 한 값이다. (ex. tombstone)
키에 대한 값은 효율성을 위해 이전 리비전과의 차이(delta)만 담고 있다. B+Tree는 키를 단순 Byte Order 로 정렬한다. 따라서 특정 리비전으로부터 다른 리비전의 수정 사항을 빠르게 찾을 수 있다. 컴팩션이 발생하면 Outdated Key-Value 쌍은 삭제되는 구조이다.
Compaction은 위에서처럼 수동으로 수행할 수도 있지만 특정 시점마다 컴팩션을 수행하도록 할 수도 있다. Compaction이 키가 사용하는 스토리지 공간을 줄여주는 것은 맞지만, 데이터를 쓰고 지우면서 생기는 단편화 문제를 해결해주지는 않는다. 단편화를 해결하려면 defragmentation(
defrag명령어)을 해줘야 한다. 이 글에서 해당 내용을 깊게 다루지는 않으므로 문서를 참고하면 좋을 것 같다.
In-memory B Tree
etcd는 일반적인 데이터베이스들처럼 캐시 레이어를 가지고 있는데, 이 부분이 In-memory B Tree이다. B Tree 인덱스의 키들이 실제 유저들(개발자)에게 노출되는 키이다. 해당 B Tree의 값으로는 키에 대한 Persistent B+Tree의 수정 내역을 가리키는 포인터를 들고 있다. Compaction이 발생하면 삭제되었던 키들(dead pointers)을 삭제하게 된다.
Reference
etcd deep dive - Data Model