Go Scheduler
Go는 많은 것들을 “알아서” 해준다. 그래서 Go는 빌드 또는 실행 옵션이 다른 언어에 비해서 적은 편이다. Go의 가장 핵심적인 부분이라고 할 수 있는 고루틴 역시 Go의 런타임에서 알아서 관리해주고 있다. Go를 사용하면서 Go의 스케줄러를 알고 있어야만 하는 경우는 많지 않지만, 더 잘 쓰기 위해 조금 디테일한 런타임 동작에 대해 알아보자.
Go Runtime Scheduler
고루틴은 런타임 스케줄러에 의해 관리된다. 아래 원칙을 기준으로 고루틴을 적절히 스케줄링 한다.
- OS Thread는 비싸기 때문에 되도록 적은 수를 유지한다.
- 많은 수의 고루틴을 실행해 높은 동시성을 유지한다.
- N 코어의 머신에서 N개의 고루틴이 병렬적으로 동작할 수 있게 한다.
스케줄러가 동작하는 4가지 이벤트가 있다. 이 이벤트를 마주하면 스케줄러가 동작할 기회를 얻게 된다.
go키워드를 사용해 새로운 고루틴을 만들고자 할 때- GC가 동작할 때
- 시스템 콜을 사용할 때
- 동기화 코드(mutex, atomic, channel)가 동작할 때
GC는 일정 시간마다 트리깅 되도록 되어있기도 하고, 힙 영역을 할당할 때 특정 값을 넘어섰는지 확인하면서 필요한 경우 GC를 트리거 할 수 있다. 링크
Goroutine이 관리되는 방식
Go는 G, M, P 구조체를 가지고 M:N 스레딩 모델을 구현하고 있다. 각각은 다음 의미를 갖고 있다.
- G: Goroutine
- M: Machine (OS Thread)
- P: Processor (고루틴을 동작시키는 가상 프로세서)
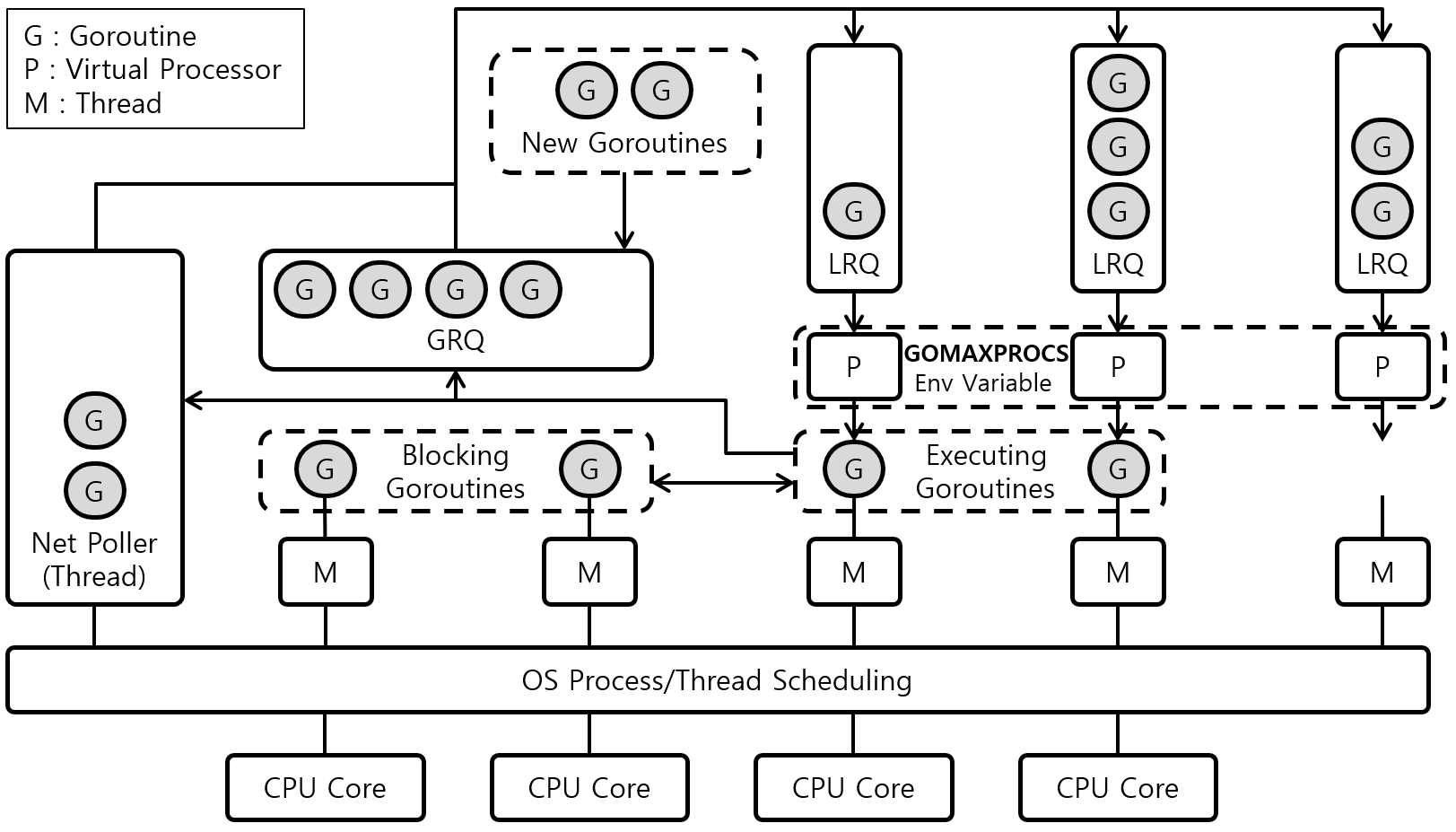
P가 G, M 사이에서 스케줄링 역할을 담당하고 OS Thread가 코드를 동작할 수 있도록 한다. 보통 아래와 같은 이미지로 표현된다.
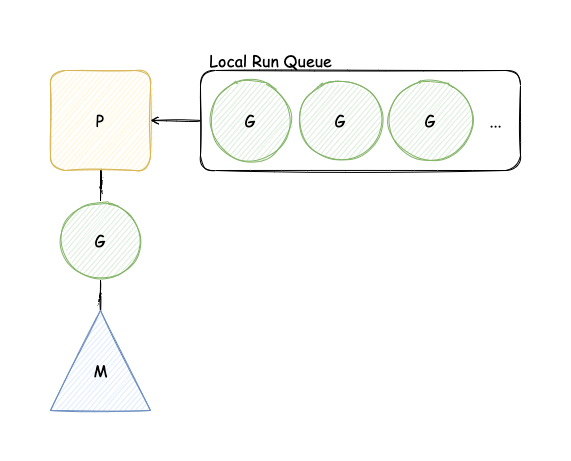
Goroutine의 상태
고루틴의 상태는 크게 세 가지로 나눠진다.
- Waiting: 이벤트 대기 상태. 시스템 콜, 동기화 콜(atomic, mutext, channel)에 의한 정지 상태.
- Runnable: 실행할 수 있는 상태. M 위에서 돌아가길 원하는 상태이다.
- Executing: 실행 중 상태. G가 P와 M과 붙어있는 상태를 의미한다.
위 그림을 확인해보면 Local RunQueue 안에 들어가 있는 고루틴이 Runnable 상태, M과 연결된 고루틴이 Executing 상태라고 볼 수 있다.
OS 스레드는 필요할 때 만들고, 재사용을 위해 남겨둔다.
스케줄러의 목적에 맞게 OS Thread는 최소로 유지된다. 다만 N개의 코어에서 최대 병렬 실행을 위한 수만큼은 생성된다. 그리고 만든 스레드는 스레드 종료 시스템 콜(pthread_exit)을 수행하지 않기 위해 유휴 상태로 남겨둔다. 이를 thread parking이라고 한다. 이렇게 유지되는 스레드를 활용해 빠르게 고루틴을 스레드에 스케줄링할 수 있다.
1 | //1. main-goroutine 실행 |
위 코드는 아래와 같이 동작하게 된다.
- 메인 고루틴을 제외하고는 다른 고루틴이 없는 상태이므로, 현재 OS 스레드 상태는
m-main한 개 g1고루틴을 생성 후 RunQueue에 담는다.- 런타임은
g1을 실행할 OS Thread인m1스레드를 만든다. - P는 RunQueue에 있는
g1을m1과 붙여준다. m1은g1프로세스가 종료되더라도 사라지지 않고 Parking(idle) 상태가 된다.
- 런타임은
- 새로
g2고루틴이 RunQueue에 올라간다. (이 시점에서g1은 종료되었다고 가정한다. 만약 종료되지 않았다면m2를 생성하고 붙여주는 위와 동일한 작업을 수행함.)- 런타임은 Parking 상태인
m1을 Unparking 후g2를 붙여준다.
- 런타임은 Parking 상태인
이때 2-2의 P는 처음 고루틴을 만들고 RunQueue에 담아준 P일 수도 있고, M이 만들어진 다음 새롭게 붙은 P일 수도 있다. 일단 여러 P 구조체가 접근할 수 있는 Global Level의 RunQueue처럼 이해하고, 이후 P의 Work Stealing을 이해한 다음 다시 생각해보자.
그런데 위에 잠깐 언급된 것처럼, 동시 실행되는 고루틴이 아주 많이 생기면 계속해서 OS Thread를 만드는 상황이 생길 수 있다. 이 문제를 해결하기 위해서는 RunQueue가 접근하는 스레드 수를 제한할 필요가 있다.
스레드 수를 제한한다.
스레드 수를 제한하지 않으면 스레드를 계속 생성하는 문제가 발생할 수 있다. 그래서 만약 스레드 수 제한에 도달하면 더 이상 스레드를 생성하지 않고 고루틴을 런큐에서 대기하도록 한다. Go에서는 이 제한값을 설정할 수 있는데 GOMAXPROCS라는 환경 변숫값을 사용한다. 최근 버전에서는 이 값이 머신의 CPU 코어 수로 설정되어 있다. 임의로 수정할 수도 있고 런타임에서는 runtime.GOMAXPROCS 함수를 사용해 설정할 수 있다.
1 | $ GOMAXPROCS=10 go run main.go |
1 | func main() { |
예를 들어 GOMAXPROCS 값이 2인 상황에서 g1이 m1 위에서 돌고 있고, g2가 생성되어 RunQueue에 들어가 있는 상황을 생각해보자.
1
2
m0 - g0 (메인 고루틴 동작 중) | RQ : [g2]
m1 - g1 (g1 고루틴 동작 중)
현재 GOMAXPROCS 만큼 M이 있기 때문에 g2는 대기하게 된다. 만약 g0 고루틴에서 동기화 블락이 발생하면 (ex. 동기 채널로 g2가 보낸 데이터를 기다린다든지…) g0은 메인 스레드에서 빠져나오게 되고 g2가 메인 스레드로 가서 실행되게 된다.
1
2
m0 - g2 (g2 동작 중) | channel wait queue: [g0]
m1 - g1 (g1 동작 중)
1 | m0 - g0 (메인 고루틴 동작 중) | RQ : [g2] |
1 | m0 - g2 (g2 동작 중) | channel wait queue: [g0] |
왜 스레드를 조절하는 이름을 꼭 프로세스 조절 이름처럼 만들었을까? 이유는 이 값의 목적은 위에서 말한 것처럼 “OS Thread 수 조절”이 맞지만 실제 동작은 “가상 프로세서 P 숫자를 제어“하기 때문이다. 말 그대로 “최대 프로세서 수”라는 뜻이다. 무슨 차이가 있는 걸까?
위에서 고루틴이 실행 상태이기 위해서는 P와 M이 붙은 상황이어야 한다고 했다. 스케줄러 역할을 해줄 P와 실제 코드를 실행해줄 M이 필요하다는 뜻이다. 즉, 실행 상태인 고루틴은 P의 숫자에 종속적이다. 따라서 스레드 수는 늘어나도 그 스레드 M이 P와 함께 있는 상황이 아니면 코드를 실행할 수 없다는 뜻이다. M과 P가 붙어있을 수 없는 상황은 바로 시스템 콜을 수행 중인 M인 경우이다. 고루틴에서 시스템 콜을 호출해 OS 스레드가 블락되게 되면 해당하는 M과 G는 P 구조체와 분리되고 P는 새로운 M과 연결되면서 RunQueue에 있는 다른 고루틴을 스케줄링한다. 블락된 고루틴은 시스템 콜 작업이 끝나면 RunQueue로 돌아오게 된다. 이렇게 스레드가 블락 되었을 때 P를 M과 G에서 떼어내는 작업을 handsoff라고 한다. 이 특징 덕분에 P가 멈추지 않고 다른 고루틴을 새로운 M에 붙여줄 수 있게 되므로 고루틴이 기아 상태에 빠지지 않도록 해준다.
고 런타임에서는 블락된 고루틴을 확인하기 위해 백그라운드 모니터 스레드를 별도로 사용하고 있다. 이 스레드는 고루틴들이 블락되는 것을 감지했을 때 유휴 상태 스레드가 없다면 새로운 M을 만들어 P에 붙여주고 만약 유휴 상태의 스레드가 있으면 해당 M과 P를 활성화한다
이러한 구조때문에 Go는 M:P:N 멀티 스레딩 모델이라고도 불린다.
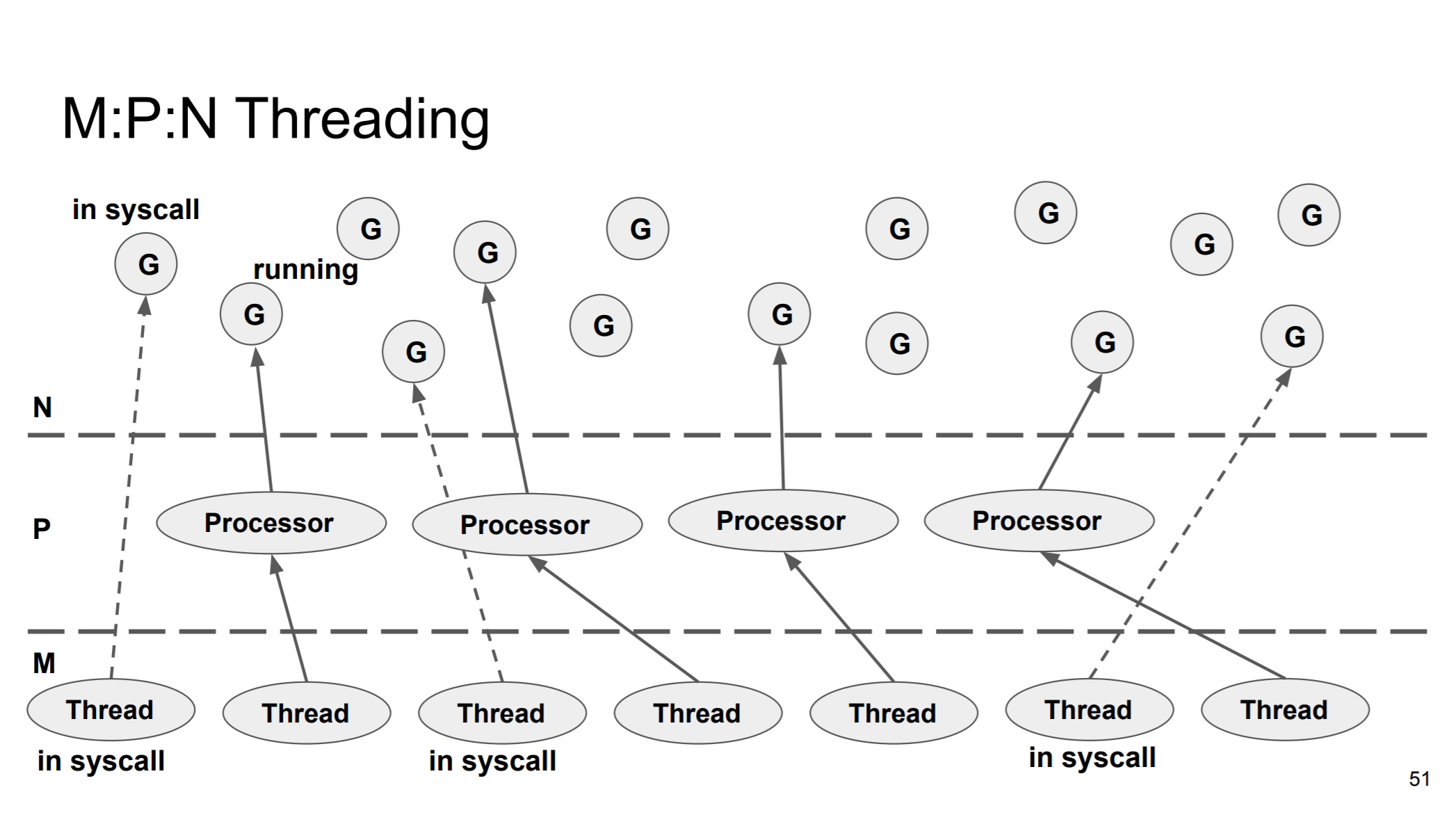
위 내용은
src/runtime/proc.go파일의handsoffp함수 주석에서 자세히 확인할 수 있다.
이런 특징이 코드를 짤 때 어떤 문제를 발생시킬 수 있을까? 우리는 GOMAXPROCS를 가지고 OS Thread 수를 컨트롤할 수 있다고 생각할 수 있지만, 실제로는 그렇지 않다는 점이다. 예를 들어서 파일 100개를 고루틴으로 동시에 열어서 작업을 수행하는 것을 가정해보자. 이 경우 블락된 OS 스레드에서 P를 분리하고 새로운 OS 스레드 M을 만드는 작업을 하므로 이론상 100개가 넘는 스레드가 만들어질 수 있다.
다음 예시 코드는 100개의 고루틴을 돌려서 파일을 만들고 쓰는 작업을 한다.
1 | package main |
1 | $ go run main.go |
시스템 콜 중 Non-Blocking I/O를 사용하는 경우가 있다. 가장 대표적으로 네트워크 I/O의 경우에는 epoll을 사용해 Non-Block으로 응답을 대기한다. 이 경우에는 M이 다른 고루틴을 수행할 수 있다. 네트워크 I/O로 블락이 발생한 고루틴은 Net Poller라고 하는 컴포넌트에서 대기하게 된다. Net Poller는 OS의 알림을 받고 고루틴을 다시 RunQueue로(특히, Local RunQueue로) 보낸다.
분산 RunQueue로 Lock 제거
RunQueue가 Global RunQueue 형태였다면 여러 P에서 고루틴을 가져오기 위해 Lock을 사용해야 한다. Go는 Global RunQueue(GRQ) 역시 사용하기는 하는데 일단 기본적으로 지금까지 설명한 내용은 Local RunQueue(LRQ)를 사용한다. 각 P 구조체마다 RunQueue를 가지고 P와 연결된 스레드의 스택을 최대한 사용한다.
또한 P가 가지고 있는 G 안에서 새로운 고루틴을 만들게 되면 이 고루틴 역시 해당 P의 LRQ에 들어가게 된다. GRQ가 사용되는 시점은 몇 가지 있지만 대표적으로 LRQ가 가득 찬 상태에서 또 새로운 고루틴을 생성하려고 할 대 GRQ로 들어가게 된다.
P가 만약 G를 M에 붙이지 않은 상태라면 M은 현재 놀고 있는 스레드라는 뜻이다. 이 상태에 있는 P와 M은 “Spinning Thread“라고 한다. 이 상태에서 P는 M에 붙여줄 고루틴을 찾아야 한다. LRQ를 가장 먼저 확인하는데 만약 P가 LRQ에 고루틴을 가지고 있지 않은 상태가 되면 임의의 P의 LRQ에 있는 작업 절반을 훔친다. 이 과정을 Work Stealing이라고 한다. 이 과정을 통해 전체 작업을 고르게 분산할 수 있게 된다. 만약 Work Steal할 대상도 없는 경우에는 GRQ를 바라본다. 그래도 가져올 게 없으면 M과 P는 Parking 된다.
Work-Stealing은 작업을 고르게 처리하도록 도와주지만, Locality를 떨어뜨린다. 고루틴은 생성 시 사용된 스레드에서 실행되어야 캐시도 활용하고 같은 메모리 스택을 사용하게 되는데 훔쳐지면 이 이점을 살릴 수 없다. 따라서 LRQ의 구조는 단순히 FIFO 구조가 아니라 맨 앞에는 LIFO 형태로 동작하는 버퍼를 사용한다.
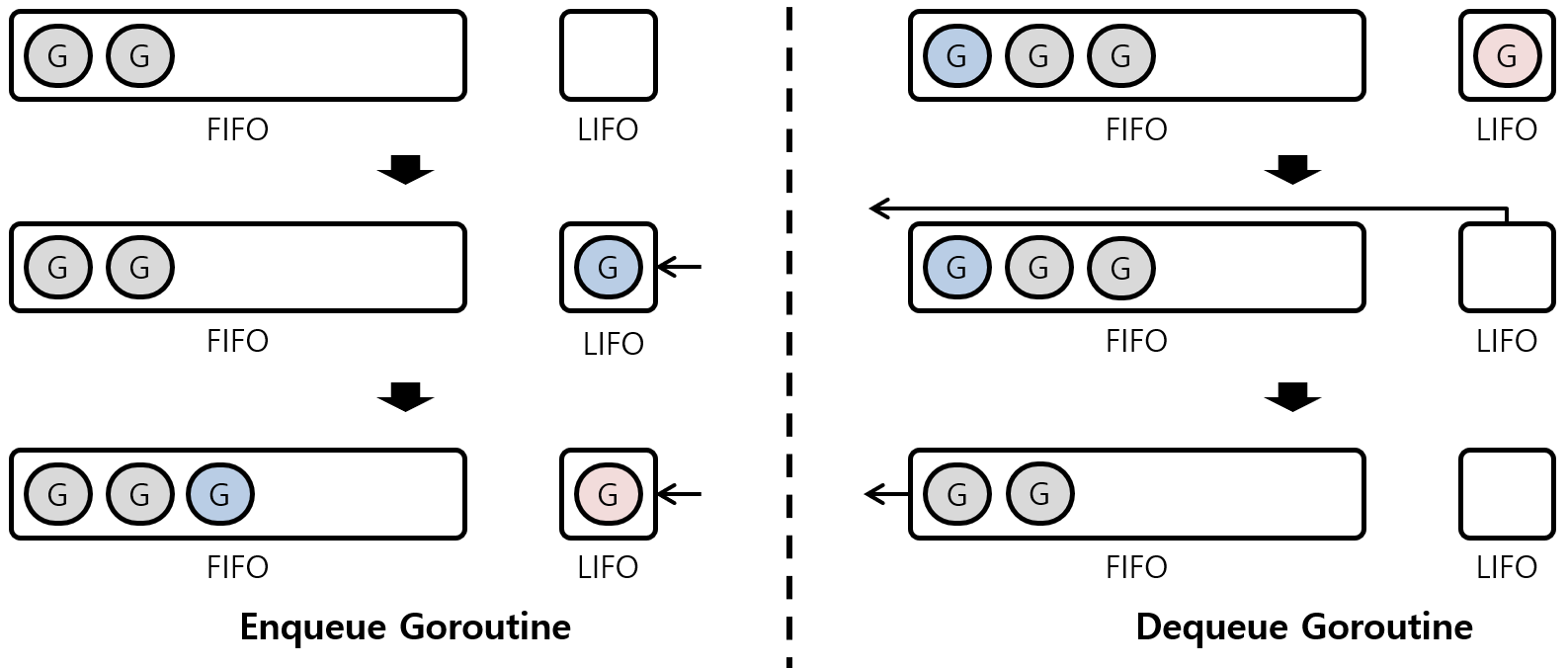
위 이미지처럼 LIFO 버퍼가 비어있는 경우 그 버퍼에 들어가고 만약 새로운 고루틴이 바로 더 들어오면 버퍼에서 밀려 FIFO 큐로 기존 고루틴이 들어가게 되고 새롭게 Enqueue되는 고루틴이 해당 버퍼 자리를 가져간다.
이 우선순위가 있는 버퍼와 함께 새로운 고루틴이 3ms 가량 Work-Steeling 되지 않는다는 규칙이 있어서 어느 정도 Work-Stealing으로 인한 지역성 저하를 보완한다.
Fairness
스케줄링의 굉장히 중요한 요소 중 하나인 공평성이 보장되기 위해 여러 기법을 적용하고 있다. 이러한 특징을 Fairness라고 부른다.
- 스레드를 사용하는 고루틴이 10ms 이상 실행되지 않도록 한다. 이 타임 스판을 넘어가면 선점되어 GRQ로 들어가게 된다.
- LRQ의 구조를 보면 2개의 고루틴이 계속 반복적으로 스레드를 독차지할 수도 있는 구조라는 것을 알 수 있다. 이를 방지하기 위해 버퍼에 들어간 고루틴은 스레드를 반납하더라도 타임 스판이 초기화되지 않는다. 따라서 한 고루틴이 이 버퍼를 차지할 수 있는 시간은 10ms이다.
- P 구조체가 고루틴을 찾는 과정이 LRQ, Work-Stealing, GRQ 순서이기 때문에 GRQ의 고루틴이 기아 상태에 빠질 수 있다. 이를 방지하기 위해서 스케줄러는 61번마다 한 번씩 LRQ보다 GRQ를 우선해서 확인한다. 61이라는 숫자는 소수 중 경험적 테스트를 통해 나온 값이라고 한다.
- Net Poller 같은 경우엔 응답을 확인하는 별도의 스레드를 사용한다 이 스레드는 G M P 구조와 별도로 동작하므로 고 런타임에 의한 기아 상태에 빠지지 않는다.
Go 스케줄러는 기본적으로 비선점적 방식이기 때문에 10ms, 3ms 등의 이벤트는 Best-Effort에 해당한다. 완전히 정확한 타이밍으로 동작하는 것은 아니다. 다만 1.12 버전 이후로 무거운 Loop가 돌면서 선점되지 않는 고루틴이 발생하는 것을 막기 위해 선점적 스케줄링 방식이 일부 도입되었다.
고루틴 재활용
고루틴이 담고 있던 코드 흐름이 모두 완료되고 나면 고루틴을 보관한다.
1 | type p struct { |
위 구조체는 P 구조체인데, gFree에 유휴 상태의 고루틴을 모아둔다. 이 리스트를 유지함으로써 유휴 상태의 고루틴을 저장하거나 뺄 때 Lock같은 동작이 필요 없게 된다.
더 나은 고루틴 관리와 분배를 위해 스케줄러 자체적으로 글로벌하게 관리하는 리스트 두 개가 있는데, 하나는 재활용이 가능한 스택이 할당된 고루틴을 보관하는 리스트와 스택 재활용이 불가능해 스택을 해제한 고루틴을 보관하는 리스트이다. P가 관리하는 유휴 상태의 고루틴이 64개가 넘어가면 고루틴의 절반이 중앙 리스트로 이동하게 된다. 이때 고루틴이 추가적인 메모리를 할당 받아 2KB보다 큰 메모리 사이즈를 가지고 있는 경우가 재활용 불가능한 고루틴으로 판단되어 메모리를 할당 해제 후 보관하고, 그렇지 않은 경우 스택 메모리도 재활용해 사용한다.
이렇게 재활용하는 특성은 OS 스레드를 계속 만드는 것처럼 비슷한 문제를 야기할 수 있다. 즉, 고루틴을 계속 만들어내는 문제가 생길 수 있다.
1 | func read(wg *sync.WaitGroup, gid int) { |
위 코드는 일단 고루틴이 생성된 다음 실행 흐름을 판단하기 때문에, 고루틴은 무조건 계속 만들어진다.
따라서 고루틴이 만들어지는 시점과 흐름을 제어해야 하는 시점을 잘 판단해서 코드를 짜야 한다.
Overall
지금까지의 이야기로 다음 이미지를 이해할 수 있게 되었다. 이 이미지를 이해하기 글에서 각 컴포넌트들을 다시 살펴보자
Reference
Go Scheduler




